
[AI 따라잡기]
조직검사·MRI 결과 등 연결, 숨은 판독 실마리 파악…
데이터 통합 통한 정보 비대칭성 개선 사례
AI를 만들 때 필요한 세 가지 기본 요소는 데이터와 알고리즘 그리고 컴퓨팅 파워에 해당하는 하드웨어다. 이 중에서 하드웨어는 대규모 장치 구매 없이도 손쉽게 사용 가능한 클라우드 서버 덕분에 보편화되고 있고 알고리즘 역시 원천 기술에 대한 투자가 없더라도 최첨단 알고리즘들이 오픈 소스 형식 또는 AI 플랫폼을 통해 제공되고 있기 때문에 개발을 시작하는데 필요한 역량을 보유할 수 있다. 하지만 데이터는 누군가에게 접근 가능한 자원으로 존재하지 않기 때문에 데이터를 중심으로 어떻게 AI를 잘 만들 것인지 고민하는 것은 의미 있다.
무슨 데이터가 얼마나 필요한지 설명하기 위해서는 AI가 풀어야 하는 미션을 잘 정의하고 있어야 한다. 전통적 관점에서 오랫동안 흔들림 없이 사용돼 온 톰 미첼의 기계 학습(machine learning)에 대한 정의에서 힌트를 얻을 수 있다. 기계 학습 관점에서 머신을 만들 때는 다음의 세 가지 요소가 제일 중요한데, 먼저 기계가 수행해야 하는 업무(task)를 명확하게 정의한 다음 해당 업무에 대한 성과를 측정하는 척도와 도달해야 하는 성공 기준을 정의해야 한다. 그러고 나서야 학습에 필요한 데이터(experience)의 종류나 규모를 논의할 수 있다. AI가 필요로 하는 데이터도 크게 다르지 않다. AI가 풀어내야 하는 업무를 명확하게 정의해 줘야 하고 해당 업무를 얼마나 잘하고 있는지에 대한 성과를 측정해 제시해 줘야 하며 그 목표를 달성하기 위해 필요한 데이터를 구해 줘야 하는 것이다.
기계학습에 대한 정의
A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on t, as measured by P, improves with experience E.
By Tom Mitchell (1988)
학습을 위한 데이터를 수집할 때도 두 가지 방법이 있는데, 인간이 직접 만든 데이터를 제공하거나 AI 스스로 자신이 학습할 데이터를 생성하도록 할 수도 있다. 예를 들어 딥마인드가 알파고를 만들었을 때는 인류가 그동안 바둑을 뒀던 수많은 대국 이력으로부터 AI가 바둑 두는 방법을 배우도록 했다면 이후 알파고 제로를 만들었을 때는 AI끼리 서로 바둑을 두게 하고 그렇게 생성된 수많은 대국의 결과에서 스스로가 학습하도록 했다. 바둑처럼 명확하게 규칙이 주어졌기 때문에 가능한 환경이었지만 알파고 제로야말로 인간의 도움 없이도 AI 간에 대결과 학습을 통해 인간의 경험에서 배운 알파고보다 훨씬 더 바둑을 잘 두는 초지능을 만들 수 있다는 증거가 됐다.
여기에서 주목해야 할 것은, 인간에 의해 이뤄지던 특징 추출(feature evaluation) 역할을 기계에 완전히 위임함으로써 인간을 뛰어넘는 성과를 만들어 냈던 것처럼 AI 학습에 사용될 데이터를 인간의 과거 경험에만 의존하지 않고 인간을 뛰어넘는 데이터를 사용한다면 모든 분야에서 알파고 제로를 만들 수 있게 된다는 것이다. 필자가 강의할 때마다 이러한 특징을 강조하기 위해 과장을 좀 섞어 우리가 만약 지구에 방문한 외계인으로부터 데이터를 얻을 수 있다면 그것을 AI가 학습하도록 해 외계인의 지적 수준을 가진 결과물을 만들어 낼 수 있다고 설명하곤 한다.
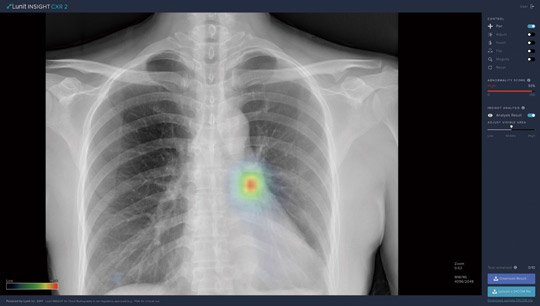
이상의 설명을 바탕으로 AI에 의한 데이터 비대칭 극복 전략을 제안한다. 이를 쉽게 이해하게 하기 위해 구체적인 사례를 살펴보자. 최근 의료 시장에서 헬스케어 AI를 테마로 성과를 인정받고 있는 루닛의 ‘루닛 인사이트(Lunit Insight)’ AI는 흉부 X선 이미지를 판독해 폐암 여부를 인간 전문의보다 더 높은 정확도로 판독하는 것으로 세계 1위의 성능을 보이고 있다.
기계라는 특징상 인간이 평균적으로 관찰하고 판독할 수 있는 데이터보다 훨씬 더 많은 데이터를 처리할 수 있다는 것은 당연하기 때문에 학습 분량 관점에서는 강점을 설명하지 않아도 될 것이다. 그 대신 무슨 데이터로 인간보다 더 뛰어난 차별화 포인트를 가져갈 것인지 새롭게 설명하고자 한다. 예를 들어 아무리 숙련된 전문의라도 X선 이미지만 봐서는 절대로 종양이 있다는 것을 알 수 없는 데이터가 있는데 종양을 판독하기에는 X선 이미지가 담고 있는 정보의 한계 때문이라고 생각할 수 있다. 더 고도화된 암 진단 방법(예를 들어 CT와 MRI)이나 조직검사 통해 얻어진 검사 결과와 같이 X선 영상 이미지 보다 더 많은 양의 정보를 담고 있는 데이터에서 종양이 발견된 사례가 있다면 상대적으로 더 낮은 정보량을 가지고 있는 X선 이미지와의 연결(pairing)을 통해 AI는 X선 이미지 속에서도 인간 전문의가 찾아낼 수 없었던 종양 양성 판정을 위한 실마리를 찾을 수 있게 된다.
AI에 이것이 왜 가능한지에 대한 직관적인 예시를 들어보면 다음과 같다. 사람의 시신경을 찍은 사진을 일반 사람에게 보여주고 남성인지 여성인지 맞히라고 하면 대부분이 맞히지 못할 것이다. 오히려 시신경 사진을 보고 어떻게 성별을 맞힐 수 있느냐고 반문할 것이다.
우리 스스로도 인공 신경망 방식을 통해 그동안 살아오면서 학습해 온 경험을 바탕으로 사람의 외모를 보고서는 성별을 거의 정확하게 맞힐 수 있지만 시신경에 대해서는 전혀 학습된 바가 없기 때문에 그렇게 느끼는 것이다. 하지만 AI는 시신경 이미지를 보고 성별을 매우 정확하게 맞힐 수 있다. 인간이 해석할 수 없는 정보를 AI가 상세하게 해석하고 성별 분류를 위한 인자로 사용할 줄 알기 때문이고 시신경 이미지 속에 이미 그러한 정보가 내재돼 있기 때문이다. 즉, AI는 인간의 눈으로는 전혀 알 수 없는 시신경 이미지 속에서 성별을 구분해 내는 특징을 파악하는 것이 남녀의 외모 사진을 보고 성별을 맞히는 것만큼이나 쉬운 일이기 때문이다.
다시 X선 이미지 판독 사례로 돌아가 보자. X선 영상 이미지 속에서도 숨겨져 있던 종양 판독의 실마리를 조직 검사 결과나 컴퓨터단층촬영(CT) 또는 자기공명영상장치(MRI) 촬영과 같은 더 고도화된 암 진단 결과와 연결해 줌으로써 서로 다른 데이터 소스에 대한 정보의 비대칭 격차를 줄여준 셈이다. 이미지 기반의 조직 검사 판독을 진행하고자 할 때도 마찬가지로 활용할 수 있다. 암세포를 실험실에서 다양한 조건에서 배양해 인간을 대상으로 얻을 수 없었던 이미지 데이터를 수집하거나 암세포에 대한 예상 이미지를 AI 스스로가 생성하도록 해 얻어진 방대한 양의 데이터를 학습시킨다면 암 진단을 더 높은 정확도로 찾아낼 수 있는 방법이 된다. 그리고 다시 X선 이미지 데이터와 연결한다면 정보 비대칭을 개선하면서 인류에게는 더 높은 가치를 제공할 수 있게 된다.
위에서 설명하는 정보 비대칭을 해결하기 위해서는 데이터 통합이 필수적이다. 동일 개체를 설명하는 서로 다른 데이터 소스를 연결하는 과정 그 차제를 통해 AI가 정보의 비대칭을 해소할 수 있게 되기 때문이다. 국가 차원에서 데이터를 통합해야 한다는 필요성과 기대 효과에 대한 점은 프랑스의 수학자이자 국회의원인 세드릭 빌라니가 주도한 AI 전략 보고서에서도 강조되고 있다. 실제로 공공 의료 데이터를 적극적으로 제공하려고 시도하고 있는데 이 글에서 설명하고 있는 것처럼 데이터 통합을 진행하면 AI가 정보 비대칭을 해소할 수 있다는 것과 지향하는 바가 같다. 이를 통해 더 낮은 정보를 함유하고 있었던 데이터의 가치가 향상되므로 그것을 활용하는 우리의 일상에 더 높은 가치를 부여할 수 있게 된다.
데이터를 통합하면 AI 학습에 사용되는 데이터의 양 또한 증가하므로 딥러닝 기반 모형의 성과 역시 증가하게 된다는 기본적인 이점뿐만 아니라 AI를 만들기 위한 데이터 바느질을 통해 데이터 유형에 따른 정보 비대칭 역시 해소될 수 있다는 인사이트를 더 많은 기업들이 활용하기를 기대한다. 이를 통해 데이터라는 자원을 중심으로 하는 AI 활용 전략을 수립하고 정보의 비대칭을 개선해 나가는 실제 사례가 늘어나기를 기대한다.
[본 기사는 한경비즈니스 제 1307호(2020.12.14 ~ 2020.12.20) 기사입니다.]
© 매거진한경, 무단전재 및 재배포 금지