[AI 이야기]
기계 학습마저 자동화한 ‘오토ML’ 주목…스스로 반복 실험 통해 최적 파라미터 등 찾아
튜닝해야 할 대상은 너무나 다양하다. 딥 러닝 모델로 한정짓는다고 하더라도 FNN·CNN·RNN·트랜스포머 등등 어떤 계열의 모델 구조를 이용하는 게 좋을까. 인공 신경망의 층수는? 한 층에 들어갈 인공 뉴런의 수, 콘볼루션 필터 사이즈와 필터 수는? 얼마나 성큼성큼 학습시키는 것이 좋을까(learning rate)? 한 번에 학습할 데이터의 수는 어느 정도가 적당할까(mini-batch size)? 몇 번이나 반복해서 보여줘야 적당할까(epoch)? 어떤 최적화 기법을 쓰고(optimizer), 손실 함수는 어떤 것을 쓰는 게 효과적이며(cost function) 활성화 함수는 무엇이 좋을까?
모델 학습을 위해 사람이 결정해야 하는 설정이 한두 가지가 아니다. 딥 러닝 기반의 AI가 머신러닝이나 룰 기반의 AI보다 수작업의 공수가 적다고 했지만 여전히 사람의 개입이 필요한 부분이 있다. 스스로 척하면 척, 알아서 학습할 수 있는 AI는 없을까.
사람이 수많은 시행착오를 겪으며 스트레스를 받지 않아도 자동으로 적절한 AI가 학습되도록 도와주는 기법이 있다. 이를 오토(Auto)ML(Automated Machine Learning), 말 그대로 자동화된 기계 학습이라고 부른다. AI가 스스로 진화한다는 표현이 좀 과장되기는 했지만 여기서 말하는 진화란 한정적인 의미다. 여기서는 ‘특정 태스크를 위한 모델 학습’에 한해 사람이 주기적으로 실험에 개입하지 않아도 AI 스스로가 반복 실험을 통해 성능을 개선하는 것을 말한다. 가만히 두면 AI 스스로가 똑똑해져 이것도 배우고 저것도 배우며 결국엔 사람을 지배하는 스토리의 진화는 결코 아니다.
오토ML의 역할은 크게 세 가지로 나눠 볼 수 있다. 첫째는 AI 모델을 학습하기 위해 데이터에서 중요한 특징(feature)을 선택하고 인코딩하는 방식에 대한 특징 엔지니어링(feature engineering) 자동화다. 둘째는 AI 모델 학습에 필요한 사람의 설정들, 하이퍼파라미터를 자동으로 탐색해 주는 것이다. 셋째는 AI 모델의 구조 자체를 더 효율적인 방향으로 찾아주는 아키텍처 탐색이다. 이미 딥 러닝 모델은 비정형 데이터를 깊은 인공 신경망에 태워 자동으로 특징을 추출한다는 장점이 있기 때문에 그중 특징 엔지니어링에 대해서는 별도로 다루지 않도록 한다.
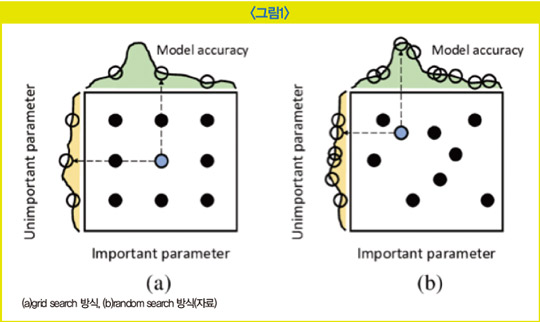
딥 러닝 모델 학습에 필요한 하이퍼파라미터는 다양한 종류가 있다. 모델의 파라미터 업데이트를 얼마만큼 큰 단위로 할지 결정하는 학습률(learning rate), 데이터를 얼마나 쪼개 학습할지의 단위인 미니배치 사이즈(mini-batch size), 데이터를 몇 번 반복 학습할지에 대한 단위 에폭(epoch), 이 밖에 모멘텀이라든지 콘볼루션 필터의 수, 스트라이드 등등 사람이 설정해 주지 않아도 자동으로 결정되는 값은 하나도 없다. 많은 경우 딥 러닝 학습 프레임워크(TensorFlow, PyTorch 등)에서는 기본적으로 잘 작동하는 설정을 디폴트로 제공하고 있다. 하지만 기본 설정으로도 학습이 잘되지 않는다면 실험 결과를 살핀 뒤 하이퍼파라미터를 조금씩 튜닝해 줘야 한다. 이게 워낙에 반복적이고 공수가 많이 드는 작업이다 보니 기존에 이미 여러 가지 하이퍼파라미터의 조합을 찾고자 하는 시도가 있었다. 자주 쓰이는 것 두 가지만 들자면 그리드 서치(grid search)와 랜덤 서치(random search) 방식이 있다.
그리드 서치 방식은 최적화할 하이퍼파라미터의 값 구간을 일정 단위로 나눈 후 각 단위 조합을 테스트해 가장 높은 성능을 낸 하이퍼파라미터 조합을 선택하는 방식이다. 단순하지만 최적화 대상이 되는 하이퍼파라미터가 많다면 경우의 수가 기하급수적으로 많아져 탐색에 오랜 시간이 걸릴 수 있다. 또한 불필요한 탐색에 시간을 허비하기도 한다. 예를 들어 (a)에서 맨 왼쪽 열의 조합들은 굳이 세 번을 다 학습해 볼 필요가 없지만 그리드 서치 방식을 이용하면 어쩔 수 없이 다 탐색을 수행해야 한다. 반면 오른쪽의 랜덤 서치 방식은 랜덤하게 하이퍼파라미터의 조합을 테스트하는 방식인데 그리드 서치에 비해 비교적 빠르게 최적의 조합을 찾아내곤 한다. 이 두 가지 방식은 어찌 보면 경우의 수를 찾는 단순 탐색법에 불과한데 단순히 ‘for문’을 이용해 구현할 수도 있다. 하지만 최근의 오토ML 방식에서는 하이퍼파라미터도 모델을 통해 탐색하곤 한다.
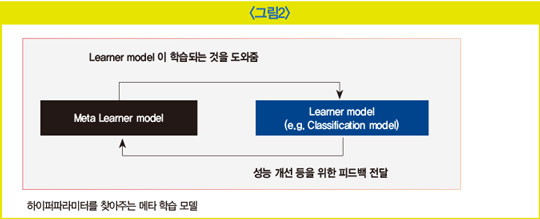
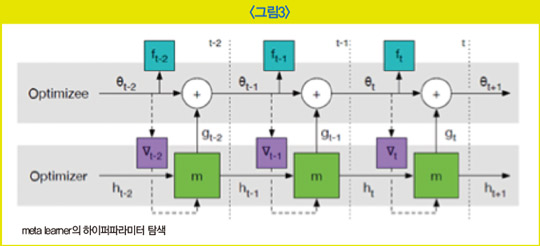
주어진 태스크를 수행하는 학습 모델(learner model)이 본래 우리가 알고 있던 AI 모델이라면 이 AI 모델이 좋은 성능을 달성하기 위한 최적의 하이퍼파라미터의 조합을 찾아주는 메타 학습 모델(meta learner)이 별도로 있다. 메타 학습 모델은 대부분 RNN과 강화 학습을 활용해 최적의 하이퍼파라미터를 탐색한다.
메타 학습 모델의 하이퍼파라미터 조합대로 학습한 학습 모델의 학습 성능 결과를 메타 학습 모델로 다시 전달하고 메타 학습 모델은 이를 또 개선하기 위한 다른 하이퍼파라미터 조합을 내며 학습 모델은 이 조합으로 또다시 학습한다. 이러한 과정을 반복하다 보면 최적의 조합을 찾아낼 수 있다. 이때 메타 학습 모델이 수행하는 학습에 대해 학습을 위한 학습이라는 뜻에서 ‘메타 학습’ 또는 ‘런투런(learn to learn)’이라고 표현한다.
아키텍처 탐색 자동화
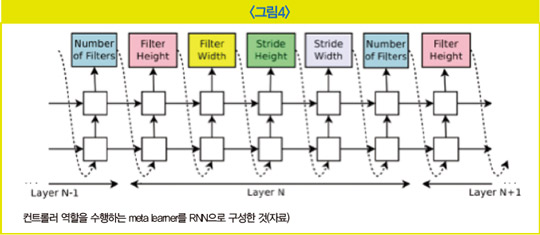
하이퍼파라미터뿐만 아니라 최적의 아키텍처를 찾아주는 방법도 있다. 아키텍처는 모델을 이루는 구조를 말하는데, 사람이 어떤 방식으로 모델 구조를 짤지 생각하지 않아도 자동 탐색을 통해 최적 구조를 찾을 수 있다. 특히 딥 러닝 모델은 인공 신경망을 활용하기 때문에 NAS(Neural Architecture search)라고 부른다. NAS도 마찬가지로 대부분 메타 학습 모델과 학습 모델로 이뤄져 있어 학습 모델이 본 과제를 수행하는 AI 모델이라면 메타 학습 모델이 어떤 구조의 신경망을 만들면 좋은지 아키텍처 구성을 고민한다.
메타 학습 모델은 역시 RNN과 강화 학습을 접목한 형식으로 구성해 볼 수 있다. 메타 학습 모델은 학습 모델의 인공 신경망 아키텍처가 어떻게 구성되면 좋을지 결정해 학습 모델의 태스크 수행 결과를 보상으로 활용한다.
이 밖에 진화 알고리즘이나 경사하강법을 기반으로 한 NAS 방식도 있다.
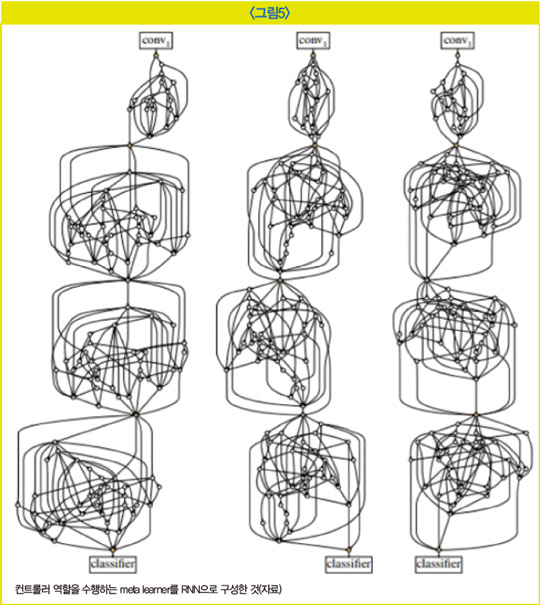
오토ML을 활용하면 사람이 한 땀 한 땀 구조를 고민하고 하이퍼파라미터를 튜닝할 필요 없이 최적의 환경을 기계가 대신 결정해 줄 수 있다. 일반적으로 오토ML을 활용하면 사람이 고안한 모델 이상의 성능을 낼 수 있다. 기계는 사람이 생각도 못한 조합의 설정이나 구조를 시도해 볼 수 있고 기존의 설정 관습이나 제약에 얽매이지 않기 때문이다.
는 2019년 AI 커뮤니티를 뜨겁게 달궜던 논문의 신경망 모델(S. Xie, et al., 2019, FAIR)인데, 오토ML을 통해 자동으로 탐색된 네트워크 구조다. 이 모델은 보기에는 임의로 엮인 실타래 같은 구조를 갖고 있지만 이미지 인식 과제에서 더 적은 FLOP 수로 사람이 만든 신경망 모델의 성능과 유사하거나 더 좋은 성능을 보였다. 기존의 NAS 방법들은 메타 학습 모델이 탐색할 아키텍처의 공간이 한정돼 있어 그중 최적의 아키텍처를 찾으려고 했다면 이 논문의 모델은 이러한 제약마저 없앤 진정한 의미의 NAS 방법을 고안했다. 이러한 모티브에서 랜덤 그래프 생성 방법론을 기반으로 아키텍처 탐색을 진행하자 처럼 기존 구성 방법의 틀을 완전히 깬 모델이 만들어졌다.
하지만 오토ML을 활용한다면 사람의 손길을 덜 필요로 하고 좋은 성능 결과를 얻을 수 있는 대신 기계가 다양한 시도를 해 보도록 오랜 시간을 기다려야 한다. 또한 고품질의 하드웨어 스펙이 뒷받침돼야만 이러한 창조적인 시도를 지원할 수 있다. 학습 모델과 메타 학습 모델이 동시다발적으로 학습해야 하기 때문이다. 결론적으로 사람이 하이퍼파라미터를 찾거나 구조를 고민하기 귀찮다면 기계에 시간과 비용을 투자해야 한다.
마무리
딥 러닝은 자동화의 패러다임을 바꿨다. 기존의 자동화 프로그래밍이 인간의 지식을 프로그래밍 언어로 명문화하여 기계에 주입하는 방식이었다면 딥 러닝은 인간의 사고방식 자체, 즉 인공적인 신경망을 기계에 구현한 뒤 수많은 데이터를 보여주며 말로 표현할 수 없는 지식을 학습시켰다. 오토ML은 여기에 다시 한 번 자동화를 추가하고 있다. 이제는 사고방식이 탄생될 수 있는 환경만 조성해 주면 기계가 알아서 나머지를 수행하게 된다. 앞으로의 AI 연구에서 사람의 역할은 태스크 수행을 위한 최적의 뇌 구조가 만들어질 수 있도록 기계를 지원하고 결과를 지켜보는 것이 되지 않을까.
[본 기사는 한경비즈니스 제 1310호(2021.01.04 ~ 2021.01.10) 기사입니다.]
© 매거진한경, 무단전재 및 재배포 금지