
[AI 이야기]
카카오가 개발한 스몰톡 챗봇…
미묘한 뉘앙스 살리는 다양한 오픈 대화 기술 활용

외개인아가에 숨겨진 인공지능(AI) 기술을 공개한다.
먼저 오픈 도메인 챗봇인 외개인아가에는 시나리오화돼 기획자의 의도에 맞게 통제가 가능한 기획 영역과 시나리오 밖의 발화들의 경우,모델에게 전적으로 위임해 처리하는 영역이 있다.
시나리오화 작업은 ‘이런 의도의 말이 들어왔을 때는 이렇게 대답해 줘’라고 설정하는 작업이라고 보면 된다. 이 작업은 생각보다 많은 정성이 들어간다. 그래서 어느 정도 예상해 분류해 둔 시나리오 이외의 말들을 커버해 줄 수 있는 기술이 필요하다.
외개인아가 제작 과정에서는 외개인아가의 페르소나와 관련된 대화나 사용자들이 많이 발화할 것 같은 대화를 ‘시나리오’로 만들었다. 시나리오 처리를 위한 모듈은 여러 가지가 있는데 가장 쉬운 방법은 봇을 만드는 빌더의 인텐트(intent)를 활용하는 것이다. 외개인아가는 카카오i 오픈빌더의 인텐트를 사용했다. 하지만 인텐트는 동일한 의도를 가진 유사한 발화의 집합이기 때문에 스몰톡의 모든 시나리오를 인텐트로만 구현하기에는 어려운 점이 많다. “밥은 먹고 다니냐”와 “밥 먹었냐”라는 질문을 모두 ‘밥을 먹었냐’와 동일한 의도로 이해하고 “저 밥 먹었어요”라고 답변할 수 있지만 인간미가 없는 기계적인 답변이라는 점에서 아쉬움이 남을 수 있다. 약간의 뉘앙스 차이를 잡아내는 것이 스몰톡의 묘미인 점을 고려해 외개인아가의 인텐트는 대략적인 ‘대화 주제’로 활용할 발화만 묶어 두고 세세한 뉘앙스 차이는 다른 모듈에서 판단하도록 했다.
좀 더 구체적인 이야기를 담아내기 위한 검색 모듈도 만들었다. 사용자가 많이 할 법한 질문과 답변 셋을 미리 만들고 검색을 통해 유사한 답변을 찾아 주는 모듈이다. 해당 모듈은 구체적인 내용의 답변을 찾아주기 때문에 외개인아가가 약간 똑똑하고 센스 있다는 느낌을 줄 수 있다는 것이 장점이다.
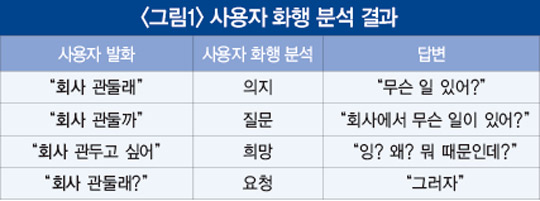
인텐트와 검색 모듈의 단점을 어느 정도 커버할 수 있는 모듈로, 사용자 발화의 화행과 엔티티를 파악해 원하는 답변을 제공할 수 있는 모듈도 있다. 예를 들어, 처럼 ‘관두다’라는 동사가 있는 발화의 답변을 정해진 답변으로 제공하고 싶을 경우 사용자 화행에 따라 적절한 답변을 제공할 수 있다.
‘ㅋㅋㅋㅋㅋㅋㅋㅋ’, ‘ㅇㅈ’, ‘ㅅㅏ줘’와 같은 초성이나 깨진 문장, 이모지(그림 문자)를 입력하거나 이미지나 동영상, ‘…’와 같은 문장 부호로만 이뤄진 발화와 같이 대화 데이터라고 하기에는 모호하지만 채팅에서 빈번하게 나오는 발화들을 처리하기 위한 모듈도 있다. 변형이 심한 언어나 특정한 의미를 가지고 있는 기호들은 사람이 봤을 때는 쉽게 알아차릴 수 있지만 컴퓨터가 이를 분석하려면 많은 모듈이 필요하다.
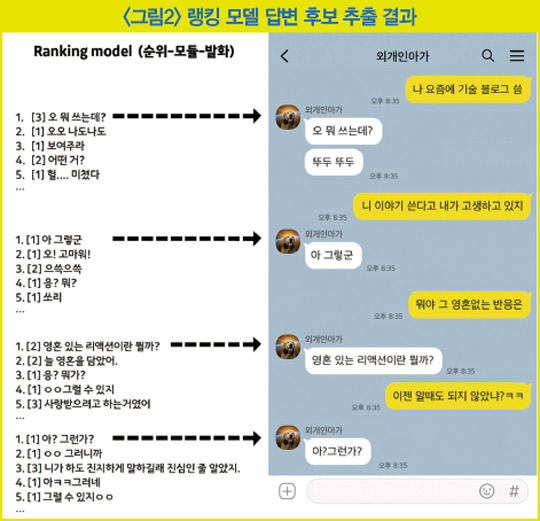
앞서 설명한 여러 모듈을 탑재하고 꽤 많은 케이스에 대해서도 시나리오 작업을 해 뒀지만 여전히 롱테일(long-tail)의 스몰톡 발화를 전부 핏(fit)하게 커버하기는 어려웠다. 스몰톡 팀은 폴백(fallback) 모델을 새로 만들었다.
폴백 모델은 시나리오화돼 있지 않은 사용자 발화에 대해 크게 세 가지 모듈에서 답변 후보를 추출하고 랭킹 모델을 태워 가장 적합한 최종 답변을 내보내는 구조로 돼 있다. 세 가지 모듈은 다음과 같다.
첫째 모듈은 스몰톡에서 사람들이 자주 많이 하는 답변을 따로 그룹핑해 ‘분류(classification)’의 방식으로 답변 후보를 추출하는 모듈이다. 이 모듈은 오타에 강건한 통합 어절 임베딩 기반의 문장 분류기를 사용했다. 답변은 대체로 길이가 짧고 간단한 맞장구치는 문장이 주를 이루고 있다.
둘째 모듈은 이미 보유하고 있는 대화 데이터에서 답변 후보가 될 만한 문장을 검색하는 모듈이다. 첫째 모듈의 일반적이고 평범한 답변보다 조금 더 구체적인 내용이 담긴 답변을 후보로 검색해 낸다. 둘째 모듈에는 문장 임베딩 모델을 활용한 의미(semantic) 기반의 검색 방법이 적용돼 있다.
마지막 셋째 모듈은 그 유명한 GPT-2 기반의 답변 생성 모듈이다. 매번 똑같은 답변을 내보내지 않기 위해 모델의 다채로운 생성 문장을 답변 후보로 사용하고 있다. 생성 모듈은 페이스북의 연구와 유사하게 방대한 웹 기반 대화 데이터를 가지고 GPT-2를 기반으로 모델을 학습시킨 뒤 팀 자체적으로 구축한 고품질의 데이터로 파인 튜닝(fine-tuning)해 성능을 추가로 향상시켰다.
폴백 모델은 이 세 개의 모듈에서 추출된 답변 후보를 모아 어느 답변이 제일 좋을지 ‘랭킹’을 매기는 모듈로 최종 답변을 선정한다. 이 모델은 구어체 대화 데이터에 특화된 SA-BERT 기법을 적용했다.
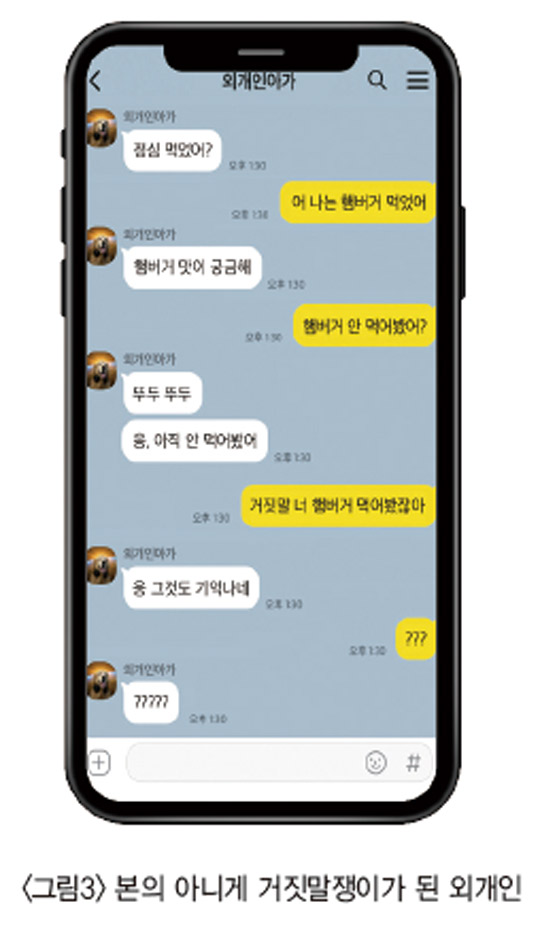
현재는 폴백 모델을 적용한 이후에도 계속 로그 트래킹을 하며 좀 더 모델을 개선하기 위해 연구하고 있다. 일단 답변 후보 중 한 축을 담당하는 생성 모델은 SOTA(State-Of-The-Art)를 찍은 다른 생성 모델들과 마찬가지로 몇 가지 한계가 있다. 고유 명사나 특정 키워드를 포함한 대화를 계속 하게 되면 학습 데이터에 있는 것만 이야기하거나 대화의 일관성을 유지하기 어려운 문제가 있다. 예를 들면 햄버거를 먹어보지 못했다고 했으면서 좀 있다가는 햄버거를 먹어 봤다는 답변을 생성할 수도 있다.
현재 랭킹 모델은 답변으로 적합하지 않은 문장인데도 이전 문맥(context)과 유사한 토큰(token)을 가지고 있으면 대체로 답변 후보로서 점수를 높게 주는 경향이 있다. 이런 한계를 개선하기 위해 새로운 알고리즘을 연구했고 이를 실제 서비스에 적용하기 위한 막바지 실험을 진행하고 있다.
이 밖에 스몰톡 팀은 다양한 노력을 하고 있다. 아직은 외개인아가의 답변이 친한 친구와 얘기하는 것만큼 재미있거나 오랫동안 이어지지 않기 때문에 많은 이들이 바쁜 일상 속에서 외개인아가의 존재를 잊어 버리곤 하는데 그런 사람들에게 먼저 말을 걸고 생일에는 축하 메시지도 보내고 있다.
2019 아마존 웹 서비스(AWS) 서밋에서 아마존은 ‘알렉사’가 사람과 20분 이상 자연스럽게 대화할 수 있도록 만드는 게 목표라고 말했다. 그런데 이 목표는 사람이 화성을 여행하는 것만큼 어려운 과제다. 아직까지는 모든 것을 언어 모델에만 위임해 오픈 도메인 챗봇을 굴러가게 할 수는 없는 것 같다. 서비스 뒤에서 알맞은 시나리오를 넣어 주는 작업이라든가 가끔 헛소리로 나가는 답변을 교정해 준다거나 하는, 나름 사람의 손을 타는 작업이 뒷받침돼야 한다.
[본 기사는 한경비즈니스 제 1305호(2020.11.30 ~ 2020.12.06) 기사입니다.]
© 매거진한경, 무단전재 및 재배포 금지