[AI 이야기]
인간이 소리를 내고 듣는 과정에 대한 이해 필수…발성 기관의 동작 공학적 모델링
하지만 AI가 음성을 이해하고 활용할 수 있도록 가르치는 것은 쉽지 않은 일이다. 사람이 몇 초면 만들 수 있는 음성 한 문장에는 너무나 많은 정보가 숨겨져 있고 다양한 목적을 가진 AI를 만들기 위해서는 각각 그 목적에 필요한 음성 정보를 이해하도록 가르쳐야 하기 때문이다. 따라서 음성을 다루는 AI를 만들려는 개발자는 무엇보다 그 자신이 음성에 대해 잘 알고 있어야 한다. 사람이 말하고 듣는 음성 한 문장에 어떤 정보들이 들어가 있는지, 이것들이 어떻게 AI를 가르치는 데 사용되는지 최대한 수식을 배제한 채 키워드 위주로 알아본다.
인간은 다양한 감각 기관을 사용해 외부로부터 오감을 인지해 정보를 입력받을 수 있다. 그중에서도 제일 자주 사용되는 시각과 청각은 가장 효과적으로 정보를 입력받을 수 있는 감각이다. 하지만 같은 정보를 담고 있을지라도 음성은 이미지와는 형태가 매우 다르고 이를 인지하기 위한 인간의 귀도 눈과 완전히 다른 방식으로 동작한다.
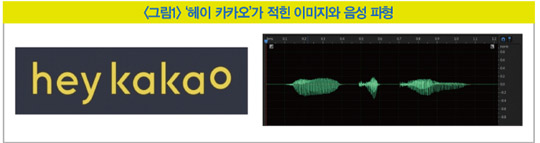
가령 ‘헤이 카카오’라는 정보가 담긴 이미지와 음성이 과 같이 주어졌다고 가정해 보자. 왼쪽 이미지를 보면 사람은 어떤 문장이 적혀 있는지 쉽게 인지할 수 있다. 하지만 음성 파형은 눈으로 봐도 어느 부분이 어떤 단어를 의미하는지 알 수 없다. 이는 컴퓨터의 관점에서도 마찬가지다. 같은 문장을 한 사람이 여러 번 발음해도 음성 파형의 값을 비교해 보면 그 분포가 제각기 매우 다르기 때문이다.
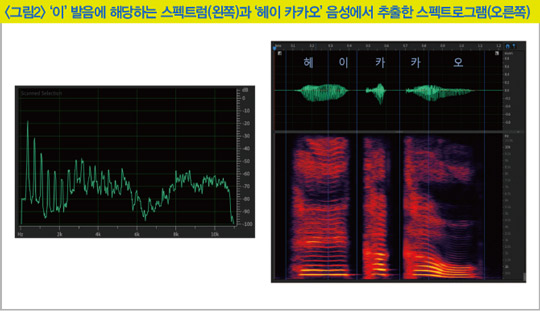
음성에 들어있는 정보(발음의 종류·성별·음색·높이 등)는 음성 신호 자체에서 쉽사리 얻어낼 수 없고 수학적인 신호 처리를 거쳐야만 추출할 수 있다. 그중 대표적인 한 가지로, 음성을 주파수라는 또 다른 축으로 관측하는 방법이 있다. 주파수는 신호가 1초에 몇 번 진동했는지를 나타내는 수치고 소리는 빠르게 진동할수록, 즉 주파수가 높을수록 음이 높게 들린다. 자연에서 들을 수 있는 모든 소리는 다양한 주파수 성분들의 합으로 이뤄져 있다.
푸리에 변환(Fourier transform)이라는 함수를 사용하면 특정 시간 길이의 음성 조각(이를 프레임이라고 부름)이 각각의 주파수 성분들을 얼마만큼 갖고 있는지를 의미하는 스펙트럼을 얻을 수 있다. 이렇게 음성 전체로부터 얻은 여러 개의 스펙트럼을 시간 축에 나열하면 시간 변화에 따른 스펙트럼의 변화인 스펙트로그램(spectrogram)을 얻게 된다. 사람의 귀 또한 이와 유사한 메커니즘을 갖고 있어 소리에 들어 있는 각각의 주파수 성분들을 추출하는 방식으로 청취한 소리에 내재된 정보들을 얻는 것이다.
사실 음성을 처리하는 데는 수많은 문제가 존재한다. 이를 해결하기 위해서는 인간이 음성을 만드는 과정과 소리를 듣는 과정을 좀 더 깊게 이해할 필요가 있다. 이러한 과정들을 수학적으로 모델링해 음성의 정보를 추출하거나 필요에 따라 가공할 수 있고 또 이렇게 얻어낸 수치들인 특징 벡터를 통해 AI가 음성을 이해하도록 가르칠 수 있다.
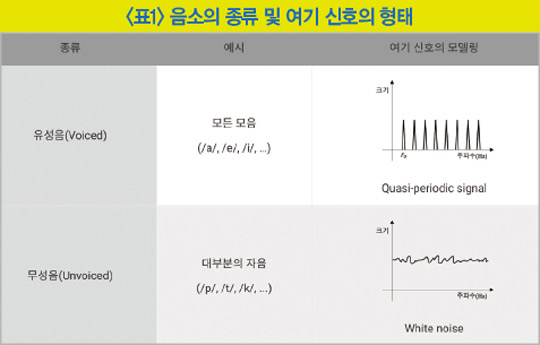
발음을 결정하는 소리의 최소 단위인 음소(phoneme)는 크게 2가지로 구분할 수 있는데, 발성할 때 성대의 진동을 동반하는 유성음과 진동 없이 성대를 통과하는 무성음이 있다(자료 : 다음백과).
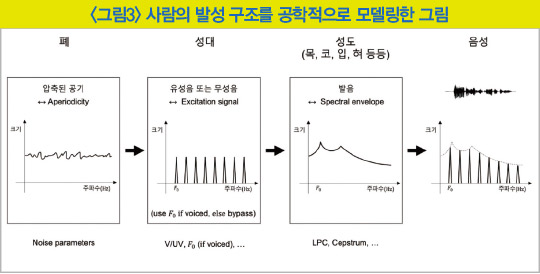
사람의 발성 구조를 공학적으로 해석할 때 성대를 막 통과한 소리를 여기 신호(excitation signal)라고 부른다. 이때 유성음 여기 신호의 파형은 준주기성을 띄게 되며 성대의 진동 속도에 따라 고유의 기본 주파수와 기본 주파수의 배수에 해당하는 여러 배음들로 전체 스펙트럼이 구성된다. 반면 무성음 여기 신호의 파형은 성대가 진동하지 않아 다양한 주파수 성분이 고르게 포함된 백색 소음과 같은 스펙트럼을 갖는다.
은 사람이 음성을 만들 때 사용하는 기관들의 동작과 이들을 각각 공학적으로 모델링한 특징 정보들의 관계를 나타낸다. 처음 폐에서 만드는 압축된 공기는 백색 소음에 가까운 비주기성 신호로, 정규 분포와 같이 쉽게 사용할 수 있는 확률 분포로 모델링할 수 있다. 성대를 통과한 직후의 여기 신호는 유성음·무성음 여부에 따라 구분되며 유성음은 기본 주파수 등의 특징을 담고 있다. 이후 목·코·입·혀 등의 성도를 통과하며 발음이 결정되는데 발음마다 성도의 구조가 달라져 증폭되는 주파수 대역과 감쇠되는 대역 역시 달라진다. 이를 스펙트럼 포락선(spectral envelope)이라고 하며 발음의 종류를 결정하는 주요한 특징으로 꼽힌다.
이렇게 각 발성 기관의 동작을 공학적으로 모델링하고 각 특징들을 추출·변환·예측하는 기술이 음성 압축, 음성 변환, 음성 합성 등의 영역에 적용돼 연구·개발돼 왔다.
음성을 듣는 과정
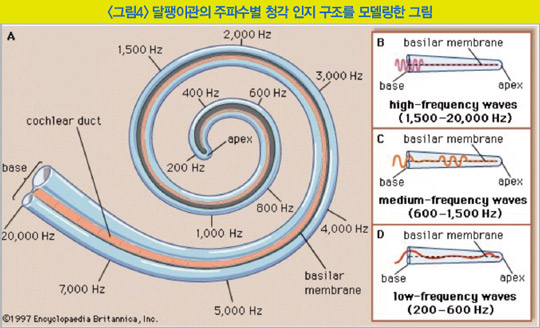
사람이 소리를 듣는 과정을 살펴보면 다음과 같다. 소리를 듣는 기관인 귀는 귓바퀴에서 소리를 모으고 고막과 이소골이 진동해 달팽이관의 청각 세포를 자극하면 전기 신호가 발생해 이를 뇌에 전달하는 방식으로 동작한다. 달팽이관은 마치 길게 늘어진 관을 돌돌 만 모양과 같고 액체로 가득 차 있는 이 관에는 청각 세포들이 일렬로 나열해 있는 코르티 기관이 존재한다. 밖에서 진동이 전달되면 코르티 기관의 특정 청각 세포가 자극돼 전기 신호를 발생시키는데 청각 세포마다 인지할 수 있는 주파수 대역이 다르다.
를 보면 달팽이관의 가장 안쪽 청각 세포는 저주파 대역을 인지하며 바깥쪽 청각 세포는 고주파 대역을 인지한다는 점을 알 수 있다. 중요한 점은 모든 주파수 대역을 같은 비중으로 인지하지 않고 고주파에서 저주파로 내려갈수록 담당하는 주파수 대역이 점점 더 조밀해진다는 점이다. 실제로 고주파 대역보다 저주파 대역에 소리의 의미 있는 정보가 집중돼 있다는 것을 생각한다면 이미 인간의 청각 구조는 보다 중요한 음성 정보에 더 집중해 들을 준비가 돼 있다는 점을 알 수 있다.
멜 스케일(mel scale)은 실제 주파수 정보를 인간의 청각 구조를 반영해 수학적으로 변환하기 위한 대표적인 방법이다. 높이가 다른 2개의 음을 사람에게 들려줬을 때 사람이 인지하는 차이와 두 음의 실제 주파수 차이를 다양하게 조사해 통계를 구축했고 이를 대략적으로 따라가는 간단한 함수로 두 단위 간의 관계를 정의했다(자료 : 위키피디아). 멜 스케일은 주파수 성분을 중요도에 따라 차등적으로 사용하기 위한 좋은 지표로, 다양한 음성 처리 분야에서 사용되고 있다.
가장 간단한 예시로 목소리의 성별을 분류하는 모델을 만들고 싶다고 한다면 목소리의 높이 정보가 담겨 있는 기본 주파수를 사용해 중간에 기준선을 긋는 것만으로도 어느 정도 분류 정확도를 얻을 수 있을 것이다. 하지만 음성 처리에는 음성 인식, 음성 합성, 화자 인식, 분류 등 훨씬 풀기 어려운 연구 분야들이 존재하며 이들을 해결하기 위해서는 우선 음성의 어떤 정보를 사용해야 하는지를 최우선으로 고민해야 한다. 대표적으로 음성을 문장으로 변환하는 음성 인식 모델을 만들려면 화자가 누구든 상관없이 문장을 동일하게 인식해야 하므로 기본 주파수와 같이 화자에 종속적인 정보보다 발음 정보와 같은 것이 더 중요하다.
MFCC(Mel-Frequency Cepstral Coefficient)는 음성 인식 영역에서 대표적으로 사용되는 특징 벡터다. MFCC를 추출하는 과정은 다음과 같다(자료 : 위키피디아).
1. 전체 오디오 신호를 일정 간격으로 나누고 푸리에 변환을 거쳐 스펙트로그램을 구한다.
2. 각 스펙트럼의 제곱인 파워 스펙트로그램에 멜스케일 필터 뱅크(mel scale filter bank)를 사용해 차원 수를 줄인다.
3. 켑스트랄 분석을 적용해 MFCC를 구한다.
켑스트랄(cepstral) 분석은 푸리에 변환을 거쳤을 때 시간 축에서 천천히 변하는 정보가 낮은 주파수 성분에 위치하고 빨리 변하는 정보가 높은 주파수 성분에 위치한다는 점에 착안한 방법이다(자료 : 위키피디아). 주파수 축에서 다시 한 번 푸리에 변환을 사용하면 천천히 변하는 스펙트럼 포락선 정보는 낮은 성분에 위치하고 빨리 변하는 여기 신호 정보는 높은 성분에 위치하게 돼 적절한 취사선택을 통해 원하는 정보가 내재된 특징 벡터를 만들 수 있다.
MFCC를 계산하는 과정은 다소 복잡하지만 그만큼 효과적인 음성 정보를 추출해 낼 수 있다. 인간의 청각 구조를 반영한 멜 스케일 기반의 필터 뱅크()를 사용해 효율적으로 특징을 압축할 수 있고 켑스트랄 분석을 통해 음성 인식에 필요한 발음 특성을 스펙트럼 포락선 정보로 구할 수 있다.
이 밖에 MFCC와 비슷한 접근법의 LPC(Linear Predictive Coding), PLP(Perceptual Linear Prediction) 등 다양한 방법론이 존재하고 음성의 시간 축 변화를 좀 더 반영하기 위해 앞서 설명한 값들의 1차, 2차 미분값을 추가하기도 하며 성능 향상을 위해 ZCR(zero crossing rate), 에너지 등을 사용하기도 한다. 이처럼 음성 특징 벡터의 종류가 다양하므로 학습하려는 모델에 알맞은 특징을 적절히 선택하는 것이 중요하다.
최근에는 하드웨어의 발달로 연산 속도와 메모리 용량이 충분히 증가했고 DNN(Deep Neural Network)에 대한 연구가 매우 활발히 이뤄지면서 복잡한 음성 도메인 지식의 요구가 최소화된 E2E(End-to-End) 방식 모델의 연구가 주목받고 있다. 아직 음성 파형 그대로를 입력받는 완전한 E2E 방식은 성능과 메모리 측면에서 갈 길이 멀지만 최소한의 특징 벡터를 사용할 수 있어 다양한 분야에서 기존의 전통적인 음성 모델들의 성능을 빠르게 추격하거나 심지어 뛰어넘고 있다.
[본 기사는 한경비즈니스 제 1307호(2020.12.14 ~ 2020.12.20) 기사입니다.]
© 매거진한경, 무단전재 및 재배포 금지